

Next: 採用する学習法
Up: RNNによる大規模なFMM(finnite Memory Machine)の学習
Previous: RNNの構成
- トレーニングセットおよびテストセット
任意のFMMを同定するには、長さ 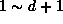 までの文字列のセットが必要で
あることが示された(Giles et al.,1994)。ここでは、2つの実験についていずれ
も d=9 であるため、長さが
までの文字列のセットが必要で
あることが示された(Giles et al.,1994)。ここでは、2つの実験についていずれ
も d=9 であるため、長さが 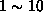 文字の2進列が必要になる。そのため、 文字の2進列全体である2046個の文字列の中からトレーニングセットを選び、残りをテスト用に取っておく。
文字の2進列が必要になる。そのため、 文字の2進列全体である2046個の文字列の中からトレーニングセットを選び、残りをテスト用に取っておく。
- 学習
ネットワークは最初に50個のサンプルにおいて学習し、それらのエラーの絶対値が0.2以内にならないと残りのサンプルを学習することはできない。また、トレーニングセットの順番は辞書順とし、エラーの絶対値が0.2より大きいものが30個以上であれば、そのエポックは打ち切ることとする。よって、ネットワークは長い文字列より先に、短い文字列を学習しなければならない。最初の50個のサンプルにおける学習が終わるとさらに50個のサンプルが加えられ、前と同じ条件を満たせば更に50サンプルが付け加えられる。ネットワークは、すべてのサンプルにおいてエラーの絶対値が0.2以内になるか、512状態のFMMに対しては5000エポック、256状態のFMMに対しては10000エポックに達したときに学習を終了する。
- テスト
汎化能力はトレーニングセットに用いていない文字列を判別する能力によってはかられる。また、このテストにおいては、実際の出力値がフィードバックされる。このことは出力値が目標値に充分近くない場合、ネットワークの能力の低下を招くことになる。それを防ぐため、テストの間出力ユニットの出力関数を階段関数とする。この結果ネットワークのフィードバック値は0,1のいずれかとなる。このことは、ネットワークのフィードフォワードの部分を論理関数としたことに相当する。
- FSMの抽出
出力ニューロンのしきい関数を階段関数に置き換えると、ネットワークは論理関数と同じ働きをする。この論理関数はFSMを定義する。このFSMは標準FSM最小化アルゴリズムによって最小化される(例えば、Hopcroft & Ullman,1979を見よ)。
Hitoshi Kobayashi
Wed Jul 26 04:25:55 JST 2000